Why did it last more than 6 hours? Facebook, Instagram cause of full down
Crying bee.
A whistleblower complaint by a former product manager on Facebook's misinformation team aired last Sunday on US news show 60 Minutes. With the shocking content, the Facebook stock went down, and this time it went down to the Facebook site. It has become an abnormal situation that "disappears" from the internet all over the world for more than 6 hours, including its affiliated services.
What caused the massive failure? Let's take a quick look back.
It started out of the blue
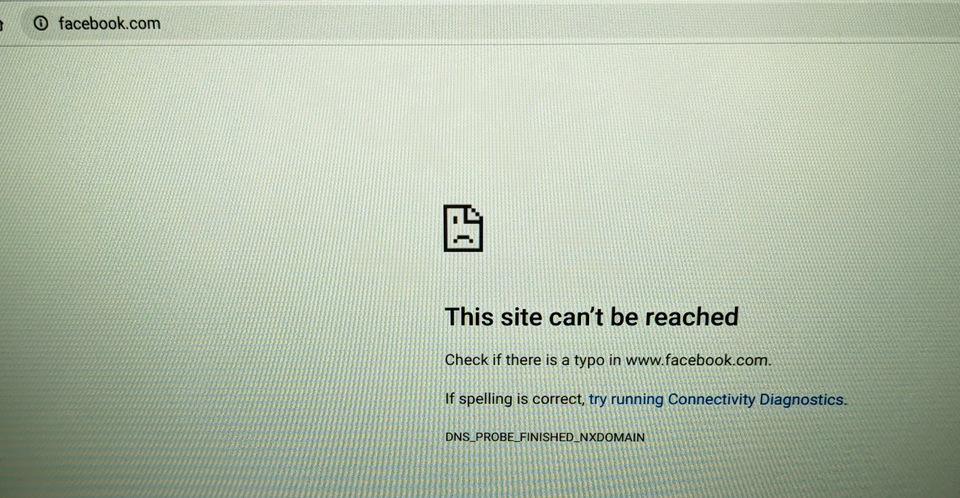
It was around 8:40AM PST on Monday when the system started to crash.
The main target is Facebook, Instagram, WhatsApp, Messenger, Oculus, and Workplace, but even those who log in with Facebook and use "Pokémon GO" etc. are also showing access errors, and they all re-access. The entire network slowed down, and complaints flooded in that they couldn't connect to Verizon, T-Mobile, and AT&T, the three largest mobile carriers in the United States.

It's a funny situation when it goes down to the failure status confirmation site "http://isitdownrightnow.com (is it down or not?)".
From all over the world, the media started making a fuss with ``I can't connect! The current status site was also down, so I had no choice but to announce it on Twitter), and a long, long day started.
Even if I try to recover, I can't enter the Facebook office!
Even though we declared an early recovery, the failure was not limited to outside the company, but Facebook's internal system also went down. Internal Tools, Workchat, Workplace, and Workplace Rooms are no longer available, and communication between employees suddenly switches to SMS and Outlook email.
The employee who rushed to the headquarters to investigate the cause was in a situation where the door would not open even if he held up his employee ID card.
In the end, we sent a small team to a data center in Santa Clara near our headquarters to manually reset the server.
Why did it take so long?
Security journalist Bryan Krebb spoke to a trusted source of the recovery, saying, "We discovered that the outage was caused by a mistake in a BGP (Border Gateway Protocol) periodic update, but we were able to remotely "People who could fix it were blocked by the patch. People in the field who had physical access didn't have access to the network. Neither of them could do anything to restore it." An absurd dilemma just like the novel "Catch22".
In the end, a man with an angle grinder (a tool that grinds and cuts metal with a high-speed rotating disk) was brought in to gain access to the server cage. One angle grinder per company. CTOs around the world may be running to buy these days.
![10th generation Core i5 equipped 9.5h drive mobile notebook is on sale at 50,000 yen level [Cool by Evo Book]](https://website-google-hk.oss-cn-hongkong.aliyuncs.com/drawing/article_results_9/2022/3/9/4a18d0792cae58836b71b9f591325261_0.jpeg "10th generation Core i5 equipped 9.5h drive mobile notebook is on sale at 50,000 yen level [Cool by Evo Book]")





![[Amazon time sale in progress! ] 64GB microSD card of 1,266 yen and wireless earphone with noise canceling function of 52% off, etc.](https://website-google-hk.oss-cn-hongkong.aliyuncs.com/drawing/article_results_9/2022/3/9/c88341f90bab7fe3ce1dc78d8bd6b02d_0.jpeg "[Amazon time sale in progress! ] 64GB microSD card of 1,266 yen and wireless earphone with noise canceling function of 52% off, etc.")
